Paris Olympics 2024 Data Engineering Pipeline
Project Overview
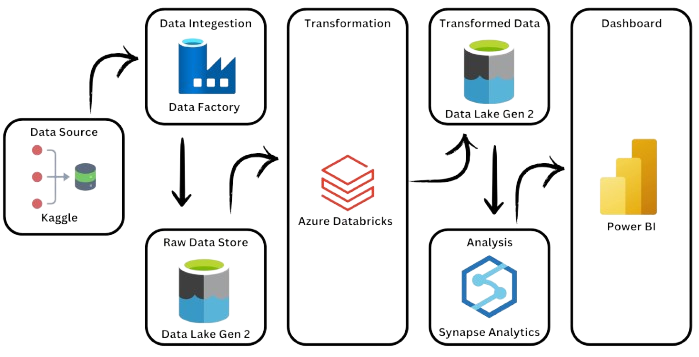
This project demonstrates the design and implementation of a full-scale data engineering pipeline using Microsoft Azure. Inspired by the global scale and complexity of the 2024 Paris Olympics, I simulated a production-grade workflow that mirrors how organizations ingest raw data, apply scalable transformations, and enable analytics and reporting.
Inspiration and Problem Context
When the Paris Olympics dominated global headlines, I challenged myself to answer a practical question: could I design a cloud-native data solution similar to what businesses use to track performance, trends, and outcomes at scale?
This project became a self-directed deep dive into modern Azure data services, with an emphasis on orchestration, scalability, and analytics readiness rather than one-off data processing.
Data Sources and Model
The pipeline ingests multiple structured datasets representing different aspects of Olympic participation and performance, including:
- Athlete details by country, gender, and event
- Coaching assignments linked by nationality
- Gender participation by sport
- Medal counts by country and discipline
Solution Architecture
1. Ingestion
- Built parameterized Azure Data Factory pipelines to ingest datasets
- Implemented scheduling and versioning logic for repeatable loads
- Ensured raw data was stored securely in Azure Data Lake Gen2
2. Processing and Transformation
- Used Azure Databricks with PySpark for scalable data cleaning
- Applied feature engineering and normalization logic
- Optimized huge datasets for performance
3. Analytics Layer
- Modeled transformed data into a star schema using Azure Synapse Analytics
- Created external tables for efficient SQL-based querying
- Prepared datasets for downstream BI consumption
Business Insights Enabled
The final datasets support dynamic analysis of:
- Medal efficiency by country
- Gender distribution across sports
- Nation-level performance trends
Impact and Outcomes
- Transformed 5+ raw datasets into a structured analytical model
- Achieved end-to-end pipeline execution under three minutes
- Delivered clean, validated datasets ready for reporting
- Built a scalable foundation supporting additional data sources